Callback 可以在模型訓練過程中觸發事件,記錄訓練過程產生的資訊、在查核點(Checkpoint)對模型存檔、迫使訓練提早結束...等,除了可以使用內建(built-in)的Callback,也可以自制(customize)Callback。
Callback搭配許多 Keras 內建的函數,可以完全解構模型訓練的過程。
以下我們就來使用一些範例,來說明Callback功能。
常用的 Callback 包括:
其他還有:
我們直接拿 MNIST 辨識作各種 Callback 測試:
# validation loss 三個執行週期沒改善就停止訓練
my_callbacks = [
tf.keras.callbacks.EarlyStopping(patience=3, monitor = 'val_accuracy'),
]
# 訓練 20 次
history = model.fit(x_train_norm, y_train, epochs=20, validation_split=0.2, callbacks=my_callbacks)
訓練 20 次,但實際只訓練 13次就停止了,因為連續三個執行週期validation accuracy沒改善。也可以改為 val_loss,只訓練 5 次就停止了。畫面如下: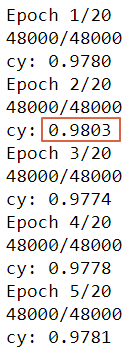
第2次準確度為0.9803,之後第3~5次都沒超過第2次,訓練就停止了。看圖也可以。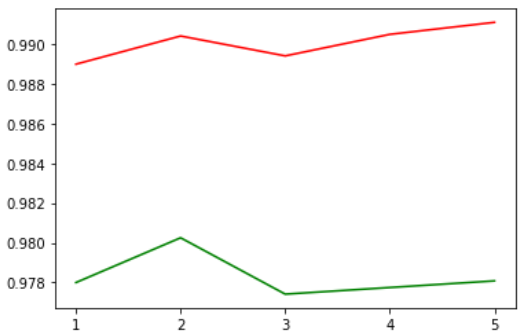
# 定義 tensorboard callback
tensorboard_callback = [tf.keras.callbacks.TensorBoard(log_dir='.\\logs')]
# 訓練 10 次
history = model.fit(x_train_norm, y_train, epochs=10, validation_split=0.2, callbacks=tensorboard_callback)
開啟 cmd/終端機,執行 tensorboard --logdir=.\logs,啟動網頁伺服器,再使用瀏覽器輸入以下網址,即可觀看訓練資訊:
http://localhost:6006/
相關資訊如下:
【Scalars】頁籤:顯示準確度與損失函數線圖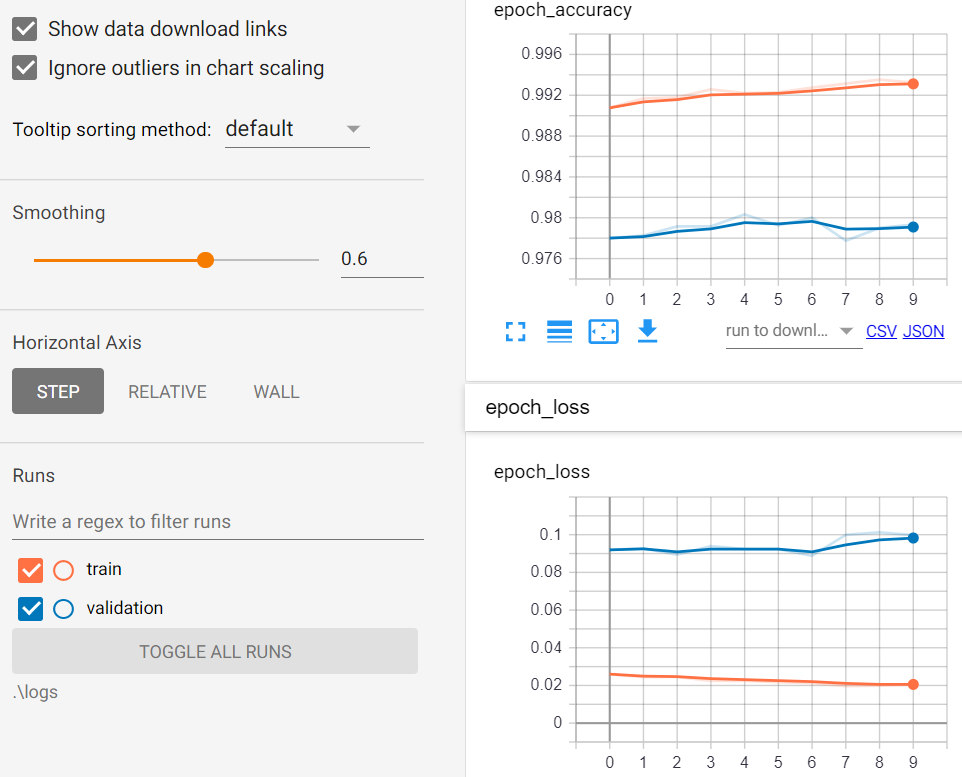
【Graphs】頁籤:顯示運算圖(Graphs)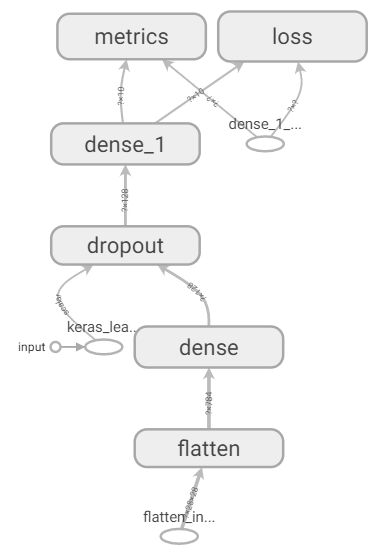
# 定義 ModelCheckpoint callback
checkpoint_filepath = '.\\tmp\\checkpoint'
model_checkpoint_callback = [tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_filepath, save_weights_only=True)]
# 訓練 10 次
model.fit(x_train_norm, y_train, epochs=10, validation_split=0.2, callbacks=model_checkpoint_callback)
下次要從最近的檢查點開始繼續訓練,如下:
# 載入最近的檢查點的權重
model.load_weights(checkpoint_filepath)
# 訓練 5 次
model.fit(x_train_norm, y_train, epochs=5, validation_split=0.2, callbacks=model_checkpoint_callback)
我們可以看到準確率(accuracy)會接續上次繼續提升,而不是回到第1次訓練時的準確率。
以上我們測了幾種常用的 callback,注意,model.fit 的參數callbacks值是一個list,可以一次加入多個callback,至於如何將更多資訊放入,就靜待下回分曉了。
本篇範例包括07_01_Callback.ipynb,可自【這裡】下載。
請問如果accuracy到達某個值之後停止訓練,callback是否有支援?
可以的。
EarlyStopping(monitor='val_accuracy', mode='max', min_delta=1)
老師請問ReduceLROnPlateau的lr跟在compile時候的optimizer 的lr有關係嗎?是相同的東西還是不互相影響
ReduceLROnPlateau的lr跟在compile的lr是相關的,訓練時會依照compile的lr運作,當訓練已無明顯改善時,ReduceLROnPlateau 可以降低學習率,追求更細微的改善,找到更精準的最佳解。
感謝老師
請教老師,老師在最後說明的這段
# 載入最近的檢查點的權重
model.load_weights(checkpoint_filepath)
# 訓練 5 次
model.fit(x_train_norm, y_train, epochs=5, validation_split=0.2, callbacks=model_checkpoint_callback)
假如我訓練跑到當機重新開始訓練會重我上一個訓練出來的接續下去嗎?
是,會從該目錄載入最新的檔案。
那 kernel 若 restart重新開始,我的epochs重跑這樣是否會影響到訓練的結果
但我若將kernel清空,假如我epochs設定10跑到2掛掉,我清空kernel重跑他一樣會跑完10個epochs還是會重第二個開始跑(抱歉老師連結無法觀看因為需要付費)
老師您好,請問要如何在 callback 的 on_epoch_end 中 print 出這次 epoch 訓練的準確度?
我目前能load model來做預測,但沒有辦法load weight
model_test = self.model
model_test.load_weights('./Weight/mbv3-{epoch:02d}-{val_accuracy:.5f}.h5')<--error
for layer in model_test.layers:
layer.trainable = False
pred_valid = model_test.predict(self.val_ds)
要取得 epoch 的準確度,使用下列程式碼即可,不需要 callback。
# 模型訓練
history = model.fit(x_train_norm, y_train, epochs=5, validation_split=0.2)
# 對訓練過程的準確率繪圖
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 6))
plt.plot(history.history['accuracy'], 'r', label='訓練準確率')
plt.plot(history.history['val_accuracy'], 'g', label='驗證準確率')
plt.legend()
感謝回答。
但history是在訓練結束"後"印出訓練過程的表現。
因為我的資料要訓練10多個小時,需要在訓練過程"中"就印出訓練的表現方便我查看,請問有辦法在on_epoch_end 中呈現嗎?
def on_epoch_end(self,epoch,logs=None):
model_test = self.model
weight=''
print("loading weight")
for fname in os.listdir('./Weight/'):
print(fname)
if "-"+str(epoch)+"-" in fname:
weight = './Weight/'+fname
print(weight)
model_test.load_weights(weight)
print("weight loaded")
for layer in model_test.layers:
layer.trainable = False
print("model predicting.....")
pred_valid = model_test.predict(self.val_ds)
print("model predict done.")
self.get_map(pred_valid, epoch)
print("totally spends {:1f}minutes.".format((time.time()-self.start_time)/60))
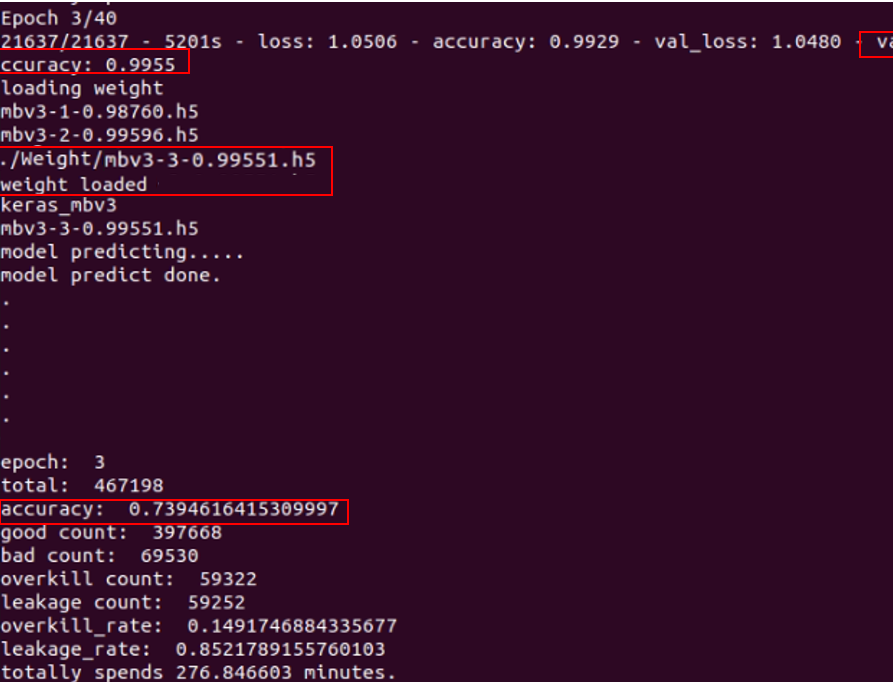
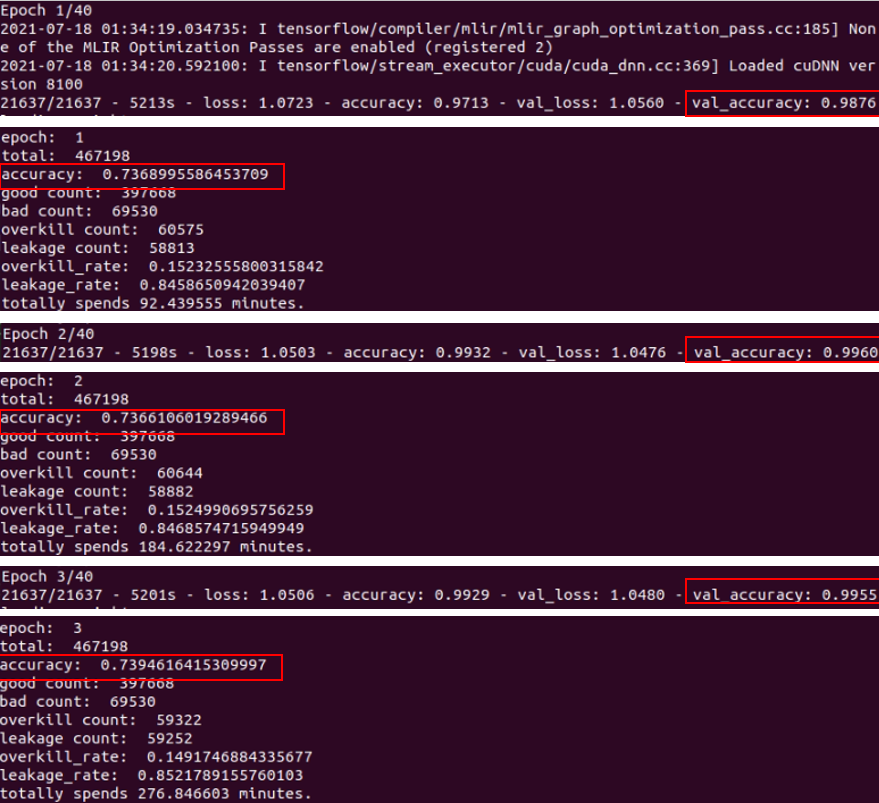
目前測試結果是可以load_weights,但是predict出來的val_acc卻跟訓練的有差距
根據每個epoch在on_epoch_end print 出來的val_acc,準確度都差不多,推測是weight都沒有load進去,都是用沒有weight的model在預測,所以準確度都差不多。
請問有辦法解決嗎? 謝謝老師!
不好意思,我沒有試過。
好的,謝謝
對了,使用 TensorBoard callback 可即時監看準確率及損失。
抓權重、損失、準確率都可以,可參考下列網址:
https://www.tensorflow.org/guide/keras/custom_callback
def on_epoch_end(self, epoch, logs=None):
print(logs)
因為我需要看的是leakage 跟 overkill 的rate 所以目前還是沒辦法解決
謝謝老師的回覆!


 iThome鐵人賽
iThome鐵人賽